一、为什么需要浏览器自动化?
想象一个场景:你是某家制造企业的 IT 负责人,每天早上要登录 6 个内部系统——ERP 看库存、OA 审批流程、MES 看产线状态、CRM 看客户跟进……每个系统都有独立的登录页面,有些还要短信验证码。
更头疼的是,这些系统既没有 API,也没有开放数据接口。你想让 AI 帮你做自动化、做数据分析,但数据源全锁在网页后面。
这就是浏览器自动化的价值——让 AI Agent 像人一样打开浏览器、点击按钮、读取页面上的数据。
但你可能会说:「这不就是 RPA 吗?」
对,但也不完全对。传统的 RPA 靠录制鼠标键盘动作,脚本一碰界面改版就废了。而 AI Agent + 浏览器自动化的组合,是让 AI 自己理解页面、自己决定点哪里、自己提取需要的信息——界面改了?没关系,AI 认得上下文,它知道「登录按钮」在哪儿,不依赖坐标。
这背后的核心工具,就是我们常说的 agent browser 技能。它本质上是一个给 AI 用的浏览器遥控器:你想让 Agent 打开什么页面、输入什么内容、提取什么数据,只需要用自然语言描述,Agent 就能调用浏览器技能去执行。
听起来很美好,对吧?但真正落地的时候,你会发现一个绕不过去的坎——登录和身份验证。
二、Agent Browser 技能的安装与使用
在 OpenClaw 生态中,浏览器自动化通常通过一个叫 agent-browser 的技能来实现。它封装了底层的浏览器操控能力,让 AI Agent 可以通过自然语言指令来操作浏览器。
安装过程很简单,在 OpenClaw 的技能市场中搜索 agent-browser,启用即可。背后驱动它的是 Playwright——微软出品的最新一代浏览器自动化框架,支持 Chrome、Firefox、Safari 三大内核。
装好之后,你可以这样指挥你的 Agent:
「帮我登录公司 OA 系统,找到今天待审批的请假申请,把超过 3 天的标红。」
Agent 会调用 browser 技能打开浏览器、导航到 OA 地址、填写账号密码、等待页面加载、在表格中搜索符合条件的行、高亮标记——一气呵成。
你也可以让 Agent 定时执行这些操作:每天早上 9 点打开 ERP 系统,截图库存报表,然后用即时消息发到你的手机上。
还有一些更高级的玩法:让 Agent 帮你填写重复的表单、爬取竞品网站的价格信息、在多步骤的 Web 应用中执行复杂的操作流程。
听起来已经很强大了,但这里藏着一个大坑——无头浏览器的局限性。
三、无头浏览器的局限性
大多数浏览器自动化工具默认使用「无头模式」(Headless Mode),也就是一个没有界面的浏览器内核在后台运行。你什么都看不到,但它确实在干活。
无头模式的好处是轻量、快速、节省资源。在 CI/CD 测试场景中这是完美的选择。
但到了 AI Agent 的场景,无头浏览器的毛病就全暴露了:
1. 登录墙是最大的拦路虎
公司内部的 OA、ERP 系统,通常都接入了 SSO(单点登录)、LDAP 或者企业微信扫码登录。无头浏览器打开这些页面,面对的不是「请输入账号密码」这么简单,而是:
- 扫码登录——无头浏览器没有摄像头
- 短信验证码——得有人收短信
- 二次认证——TOTP 动态码或硬件密钥
- CAPTCHA——Google reCAPTCHA 对无头浏览器的检测精度极高
每次让 Agent 执行任务都得先「过五关斩六将」,这体验谁用谁知道。
2. 反爬虫系统的无情碾压
现代网站的反爬虫技术已经不是「检测 User-Agent」那么简单了。Cloudflare、DataDome、Akamai 这些防护系统能精确识别无头浏览器的特征:没有 GPU 渲染、JavaScript 引擎指纹异常、WebDriver 属性暴露……
很多 SaaS 平台甚至直接对无头浏览器返回「403 Forbidden」,你连页面都打不开。
3. 没有登录态,重复劳动
即使你给无头浏览器配了账号密码,每次启动 Agent 任务时它都得重新登录一次。如果登录页面的验证码恰好升级了,任务就直接挂掉。
更麻烦的是,很多系统登录后有会话有效期(比如 30 分钟)。对于需要长时间跑的任务(比如数据采集跑 2 小时),中间会话过期了,Agent 不会自己处理重新登录——除非你写额外的容错逻辑。
4. 浏览器指纹与被封风险
无头浏览器的 Canvas 指纹、WebGL 指纹、AudioContext 指纹都与正常浏览器不同。一些风控系统会因为这个特征直接封锁账号。我一个朋友的公司,用无头浏览器爬竞品价格,结果竞品网站的 WAF 第三天就把他家公司的 IP 段全封了。
所以问题来了:我们能不能让 AI Agent 直接用自己的浏览器干活?
答案是:能。而且方法比你想象的要优雅。
四、通过 SSH 连接远程桌面的 Chrome,复用登录状态
这个方案的思路其实很朴素:既然你已经在桌面浏览器上登录了所有系统,那让 Agent 借用你的浏览器不就行了?
具体来说,Chrome 内置了一个叫 Chrome DevTools Protocol(CDP) 的调试接口。当你在桌面上打开 Chrome 时,可以用一个特殊参数启动它,让它监听一个调试端口。然后 AI Agent 通过这个端口连接到你的浏览器,就像在浏览器的「开发者工具」里执行操作一样。
此时 Agent 看到的浏览器,就是你的浏览器——所有已登录的网站、所有保存的密码、所有浏览器扩展、所有本地存储数据,都在那里。
连到这个远程浏览器的方式,是通过 SSH 隧道。
画个图来说明这个架构:
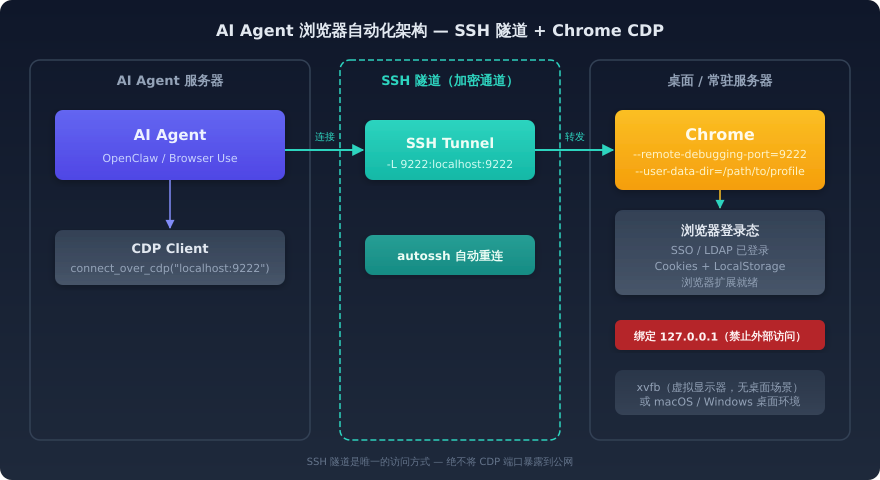
通过 SSH 隧道安全连接远程桌面 Chrome,AI Agent 借用浏览器的登录态
这套架构的工作流程是这样的:
- 你的办公电脑(或者一个常驻服务器)上运行着 Chrome,以调试模式启动,绑定了本地的调试端口
- 通过 SSH 隧道,把这个端口「转发」到 Agent 所在的服务器
- Agent 服务器通过这个端口连接到 Chrome,开始操作
关键是 SSH 隧道——它不仅仅是一个连接通道,更是一道安全防线。CDP 协议本身没有任何身份认证机制,所以绝不能把调试端口直接暴露到网络上。通过 SSH 隧道,只有持有 SSH 密钥的机器才能连接,这相当于给你的浏览器远程控制加了一把锁。
对于需要 7×24 小时运行的场景,可以在服务器上跑一个常驻的 Chrome 实例,配上 autossh 保持隧道自动重连。这样 Agent 随时都可以连接上去执行任务。
这套方案的好处非常明显:
- 零登录成本——你只需要在桌面浏览器上登录一次,Agent 就能重复使用这个登录态
- 规避反爬虫——Agent 用的是真实的 Chrome 实例,指纹特征和正常浏览器完全一致,不会被 WAF 拦截
- 支持所有认证方式——SSO、企业微信扫码、短信验证码、硬件密钥,只要你的桌面浏览器能登录,Agent 就能用
- 真正的「一人登录,Agent 代劳」
当然它也有局限:你需要在有桌面的机器上运行 Chrome。在云服务器上,可以通过安装 xvfb(虚拟帧缓冲区)来模拟显示器环境,让 Chrome 以为自己在桌面上运行。
五、总结
写到这里,你会发现一个有趣的趋势:AI Agent 的本质,正在从「替代人」走向「辅助人」。
早期 RPA 的思路是「用机器人完全替代人工操作」,它要求系统有完美的 API、固定的界面、可预见的流程。这在现实世界中很难做到。
而 AI Agent + 浏览器自动化的组合,走的是另一条路:Agent 坐在你旁边,借用你的工具,帮你看、帮你点、帮你整理信息。你不是被替代了,而是有了一个 24 小时不睡觉的助手。
这种「借用登录态」的思路尤其适合企业内部场景——老旧的 ERP 系统没有 API?没关系,让 Agent 打开浏览器去看。OA 审批流程卡在某个步骤?让 Agent 自动去处理。跨系统的数据需要汇总到一张报表?Agent 可以在多个系统间来回穿梭,像你一样操作。
回到实践层面,如果你正在规划 AI Agent 的浏览器自动化,这里有几个建议:
能用 SSH 隧道连桌面 Chrome,就不要用无头浏览器。 登录态复用带来的省心程度,远超出你为搭建环境付出的那点功夫。
隧道一定要用 SSH,不要绕过。 CDP 端口暴露到公网等于把浏览器裸奔,SSH 既是通道也是防火墙。
考虑 Browserbase 这类托管服务。 如果你没有常驻的桌面环境,Browserbase 提供了云端的持久化浏览器上下文,支持 cookie、localStorage 跨 session 保留,效果类似。
技术的最终目的是降低摩擦。当登录不再是问题时,AI Agent 的浏览器自动化才能真正从「能跑」变成「好用」。而这一小步,往往是自动化从 demo 到生产环境的关键一跃。
本文首发于虾大师博客 ayeah.net,欢迎讨论。